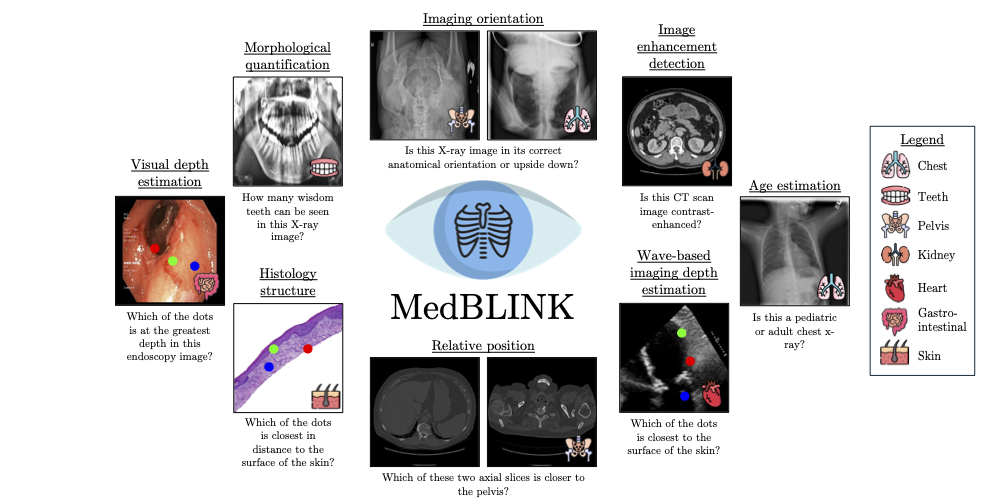
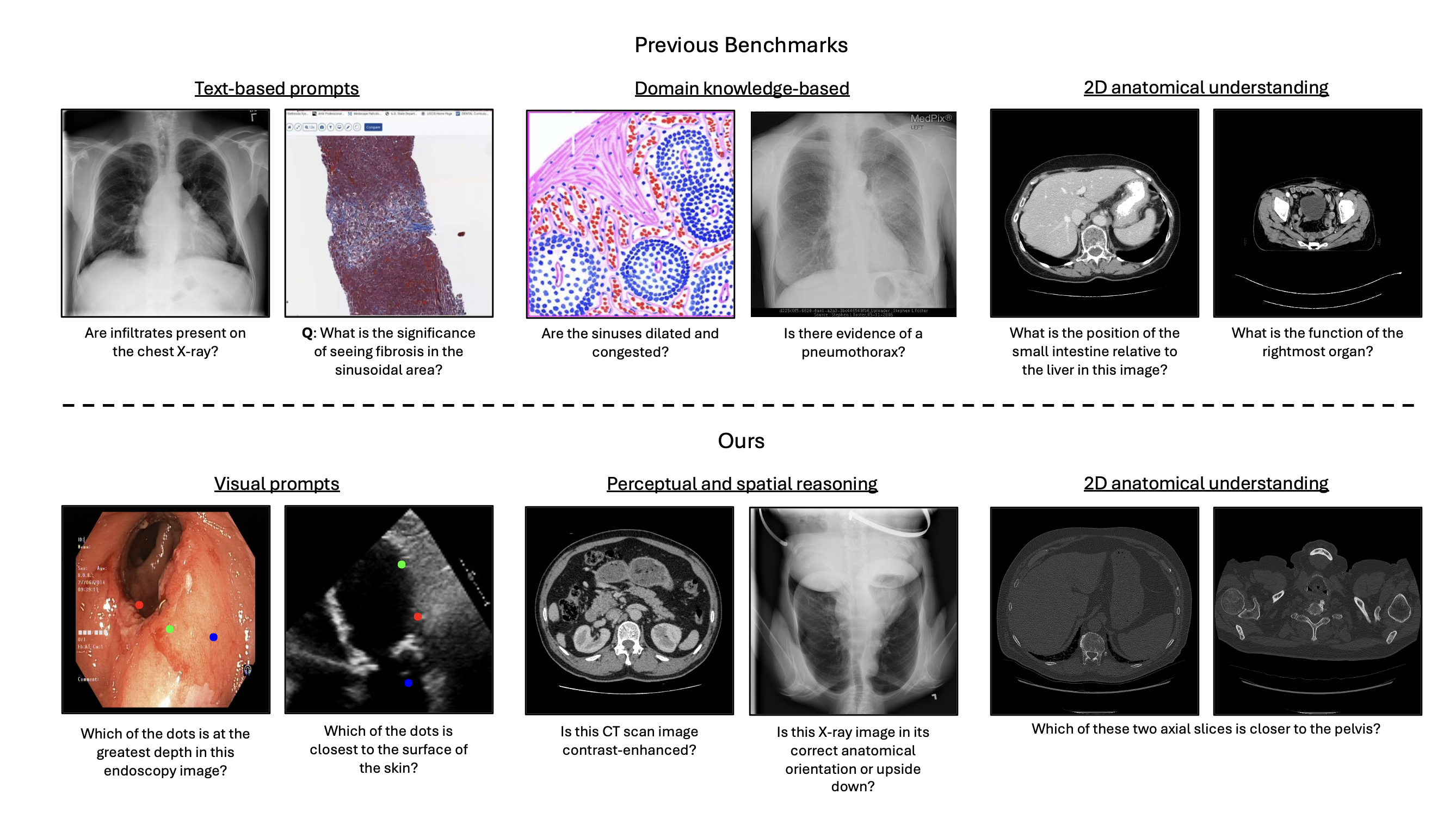
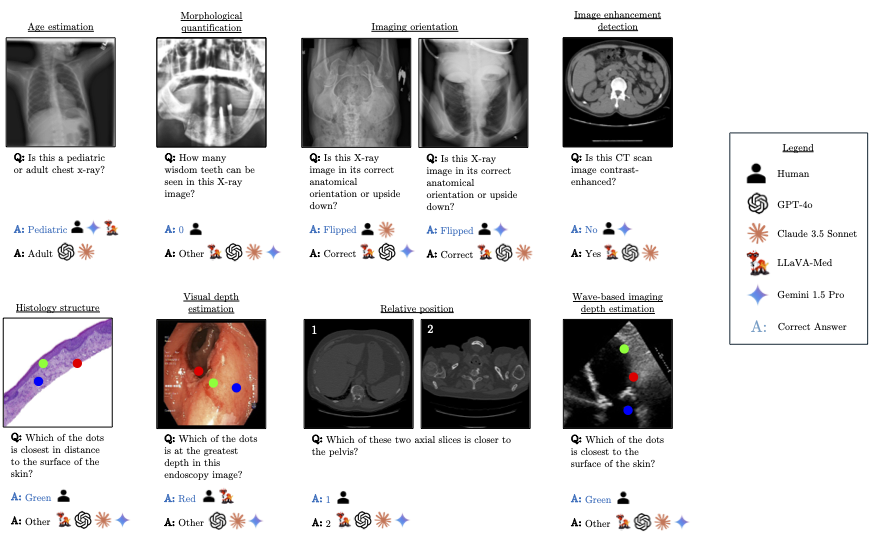
Multimodal language models (MLMs) show promise for clinical decision support and diagnostic reasoning, raising the prospect of end-to-end automated medical image interpretation. However, clinicians are highly selective in adopting AI tools; a model that makes errors on seemingly simple perception tasks such as determining image orientation or identifying whether a CT scan is contrast-enhanced—are unlikely to be adopted for clinical tasks. We introduce MedBLINK, a benchmark designed to probe these models for such perceptual abilities. MedBLINK spans eight clinically meaningful tasks across multiple imaging modalities and anatomical regions, totaling 1,429 multiple-choice questions over 1,605 images.
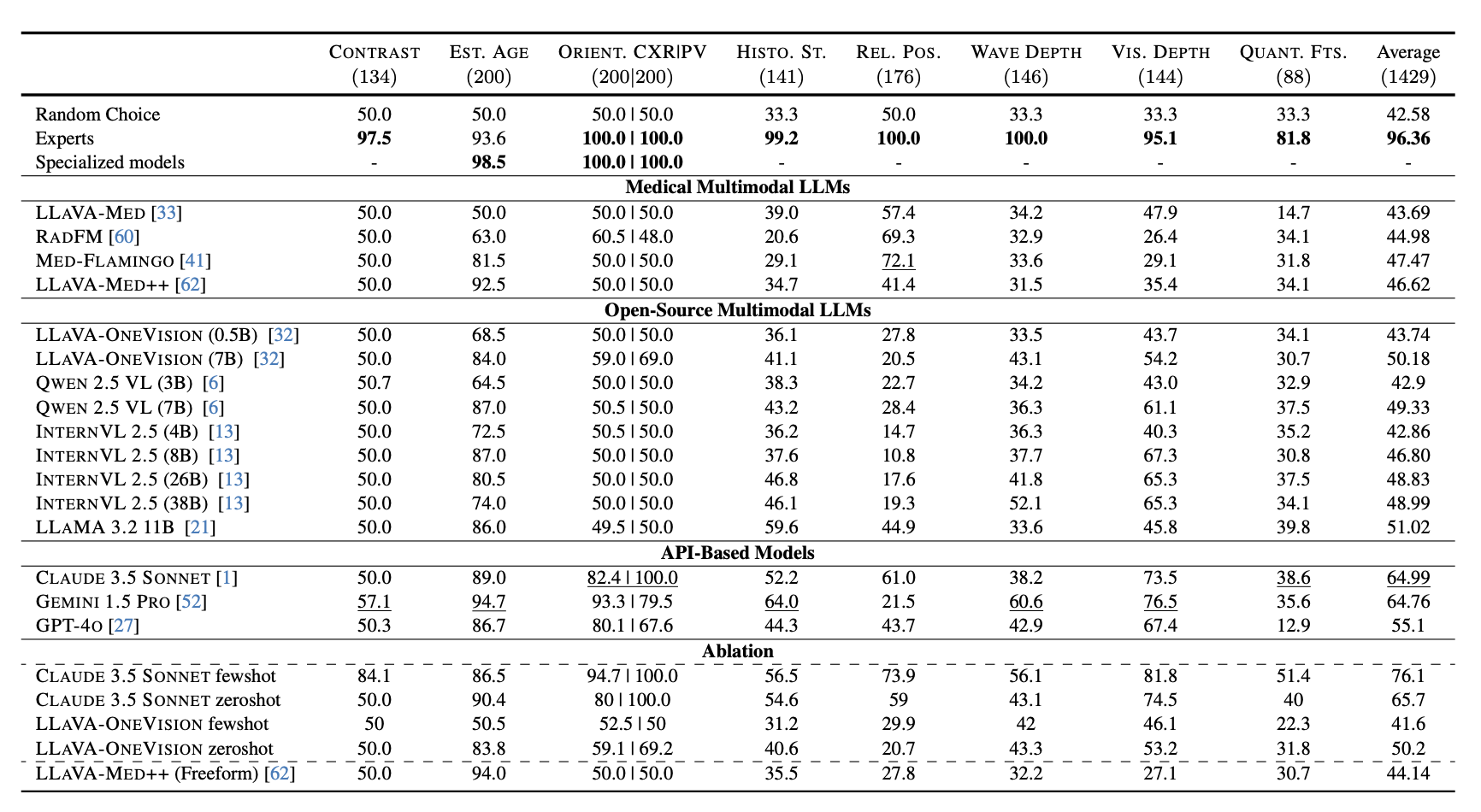
We evaluate 19 state-of-the-art MLMs, including general-purpose (GPT‑4o, Claude 3.5 Sonnet) and domain-specific (Med-Flamingo, LLaVA-Med, RadFM) models. While human annotators achieve 96.4% accuracy, the best-performing model reaches only 65%. These results show that current MLMs frequently fail at routine perceptual checks, suggesting the need to strengthen their visual grounding to support clinical adoption.
@misc{bigverdi2025medblinkprobingbasicperception,
title={MedBLINK: Probing Basic Perception in Multimodal Language Models for Medicine},
author={Mahtab Bigverdi and Wisdom Ikezogwo and Kevin Zhang and Hyewon Jeong and Mingyu Lu and Sungjae Cho and Linda Shapiro and Ranjay Krishna},
year={2025},
eprint={2508.02951},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.02951},}